最近利用してるエージェントとモデル (2026-04)
スナップショットとして記録しておきたいので、雑に書いておく。
契約内容
- GitHub Copilot Enterprise Plan
- copilot cli
- チャージなし
- Claude Code Max Plan x20
- claude code
- チャージあり
- Codex Business Plan
- codex cli / codex app
- チャージなし
- Cursor Pro+ Plan
- agent
- チャージなし
- 足りなくなったら Ultra プランへ切り替え予定
所感
感触なので根拠があるとかは特にないので、それを前提として欲しい。
GitHub Copilot
Copilot が恐ろしく効率が良い。1000 Premium Request が含まれているのだが、GPT 5.4 extra High で利用しても、全く減らない。トークンベースではないので、リファクタリングやデバッグなどに利用すると 6 時間ぶっ続けて利用しても premum request が 10 減るくらい。10 だと 1 Puremium Request が追加では 0.04 ドルなので 160 円計算で 6.4 円 ... 。
めちゃくちゃ複雑な通信のフレーキーなデバッグを対応してもらってた。内容。デバッグなので変更差分は小さめ。
Changes +819 -459
Requests 13 Premium (10h 17m 32s)
Tokens ↑ 21.8m • ↓ 134.3k • 20.7m (cached) • 88.4k (reasoning)ただチョットした質問や細かく指示する場合は Premium Request がサクサク減っていいので「大きめのタスクを通すための依頼をする」というのが向いている。
リファクタリングやデバッグの時間がとても長くなるような製品を作ることが多いので、かなり助かっている。特に E2E テストはしっかり作りこんでいくことになり、ありがたい限り。
Claude Code
Opus 4.7 xhigh で利用。死ぬほど細かく指示をしながら利用している。自分がコード書かないだけくらいのというスタンスで利用している。
issue (GitHub Issues ではなくリポジトリの中に issues/ というのを作って md で書いてる) をプランでしっかり作って issue を読むだけで実装できるところまで追い込む。
つい最近まで「疲れて」いたのか、かなり残念な結果を返すことが多かった。ただ GPT 5.4 や 5.5 の方が安定感があるので「代理作業者」的な用途で使うことが多い。
自分の代わりにコード書いてもらう程度に抑えてるので、期待はしてない。
Codex
Codex App を使って、コードレビューに利用している。レビューの質が良い。Claude Code と連携させてレビューを徹底的にさせてる。
GPT 5.5 中 (日本語表記) で利用して、なんどもなんどもしつこくレビューさせるという方針。Codex でレビューした結果を自分でもレビューして突っ込んだりしている。
Claude Code で作成した Issues のレビューもしている。
Cursor
agent (Cursor の CLI) で Composer 2 Fast (MAX) を利用している。恐ろしく早いので主に調査とプロトタイプに利用している。
Pro+ で $60 なのと、まだ Ultra (x20) があるので、足りなくなってもまだ余力がある。今月は 75% くらいで 13.5 億らしい。とにかく調査が早くていい、ソースコードを読んだり理解するのに使ってる。
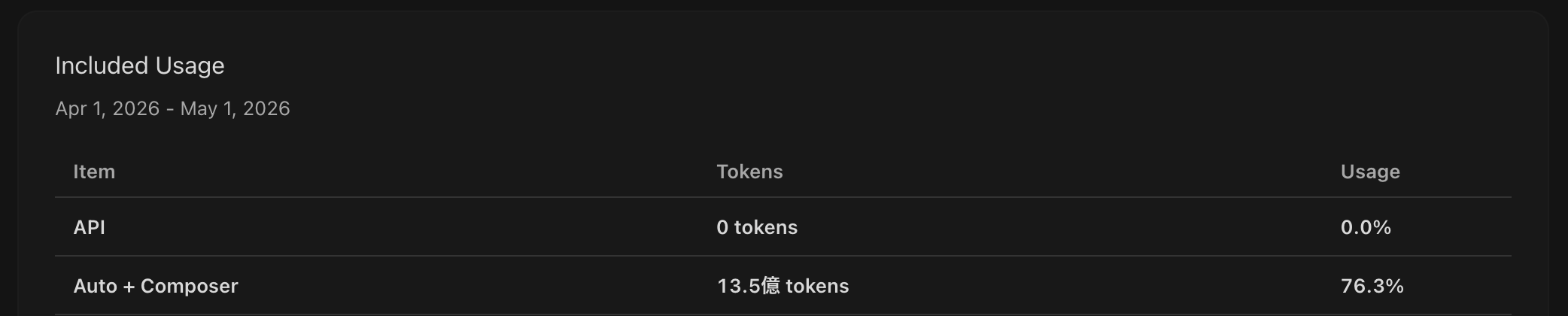
Composer 2 は Kimi 2.5 ベースらしく、Kimi 2.6 が気になってるが、まぁそのあたりは気にならない。
Cursor は Copilot と同じでいろいろなモデルも利用できるので、Cursor は悪くないなと思う。トークンをほぼ気にせず使いまくれるといのは体験としてとても良い。
ローカル LLM
全く興味なくて手を付けていない。今のところはお金を払ってサービスを利用した方が良いと判断している。ただこれからサービス利用料が値上げしていくんだろうなと思っているので、手を出しておくのは良さそう。
Kimi 2.6 とか DeepSeek v4 とか名前だけ追いかけてる。