Markdown へ
時雨堂ではほとんどの公開ドキュメントは Sphinx というドキュメントツールにカスタムテーマを開発して利用している。Sphinx では reStructuredText (rst)というマークアップ言語を利用する。
世は Markdown 一強へ
LLM の影響もあり、今はほぼ Markdown (md) 一強。ただ、どうにか rst で生き残るために試行錯誤していたが、Claude Code の Skills を使った時に「あぁ、もう md しか世界に受け入れてもらえないんだな」と実感し、rst から md への切り替えを決心した。
rst から md へ
rst というか Sphinx はドキュメントツールなので色々便利な機能が沢山入っている。これをただの md に切り替えるのは現実的ではない。
そのため、ドキュメントツールを検討することになる。何年も前から試したりしていたが、しっくりくるツールを見つけられなく 1 年以上は Sphinx でなんとかしのいできた。ただもう md にしないともうだめだ ... と思い本格的に調べ始めた。
あと rst ってぐっとくる linter や formatter がない、Markdown は markdownlint があり、VS Code 拡張も便利なので rst からなんとか移行したいなと思っていた1つではある。
アンカー ID 指定
Sphinx の label (.. _spam)を定義して :ref:`spam` でアクセスする仕組みがほしい。簡単に言えばアンカー ID を指定することができる仕組み。これは Markdown 自体にはないのでドキュメントツール独自のツールになるという認識。
アンカーリンクを作る事自体はできるが、欲しいのは ## スパム とかに #spam でアクセスできるようにしたい。
MDX 対応
md だけでは表現力が低すぎるので MDX が利用できることは必須。MDX は md の拡張で React でやりたい放題できる。
そして rst ってビルドが死ぬほど遅い、本当に遅い。なので早い方がいい。コンパイルのはやい MDX ライブラリを採用しているツールが良いなとぼんやり思っていた。
md コピペ
見ているドキュメントにコピペボタンが付いていて md そのままコピペできるのは必須な時代にったと思っている。LLM にコピペでそのまま渡したいはず。
md URL
最近多い、URL のお尻に .md を付けると md が取得できる仕組み。/spam というパスがあるのなら /spam.md とするだけで md が取得したい。エージェントが自動で読み込むとき相性がいい。
検索対応
ドキュメントの検索機能っておまけが多くて、結局は Algolia を使ってね系が多いので、そこはカスタマイズすることが出来るのは凄く重要。
そもそもドキュメントツールが期待する日本語全文検索機能を積んでいることなんて絶対無いので、ここは好き放題にいじれないと困る。
多言語対応
今までは日本語のみだったが、ちょっと今作っている OSS は世界でも利用してほしいので (PLaMo 翻訳を利用して) 英語と中国語に対応したいという思いがあり、多言語対応もしたいなと考えていた。
ウェブページとドキュメントの両方を実現
基本的に時雨堂の OSS はウェブページはメンテがめんどくさいので作らないが、それでも作りたい OSS もあるので、ウェブページとドキュメントの両方を提供できるのが良いなと思っていた。
これらを踏まえて色々しらべたら Rspress というドキュメントツールを見つけた。
# スパム {#spam}という形式でアンカー ID を指定できる- Rust 製の高速な MDX ライブラリを自前で開発して採用している
- 検索を拡張できる
- md コピペと md URL を拡張するプラグインがデフォルトで用意されている
- 多言語対応できる ja と en とかディレクトリを掘るだけでいい
- ウェブページっぽいこともできる
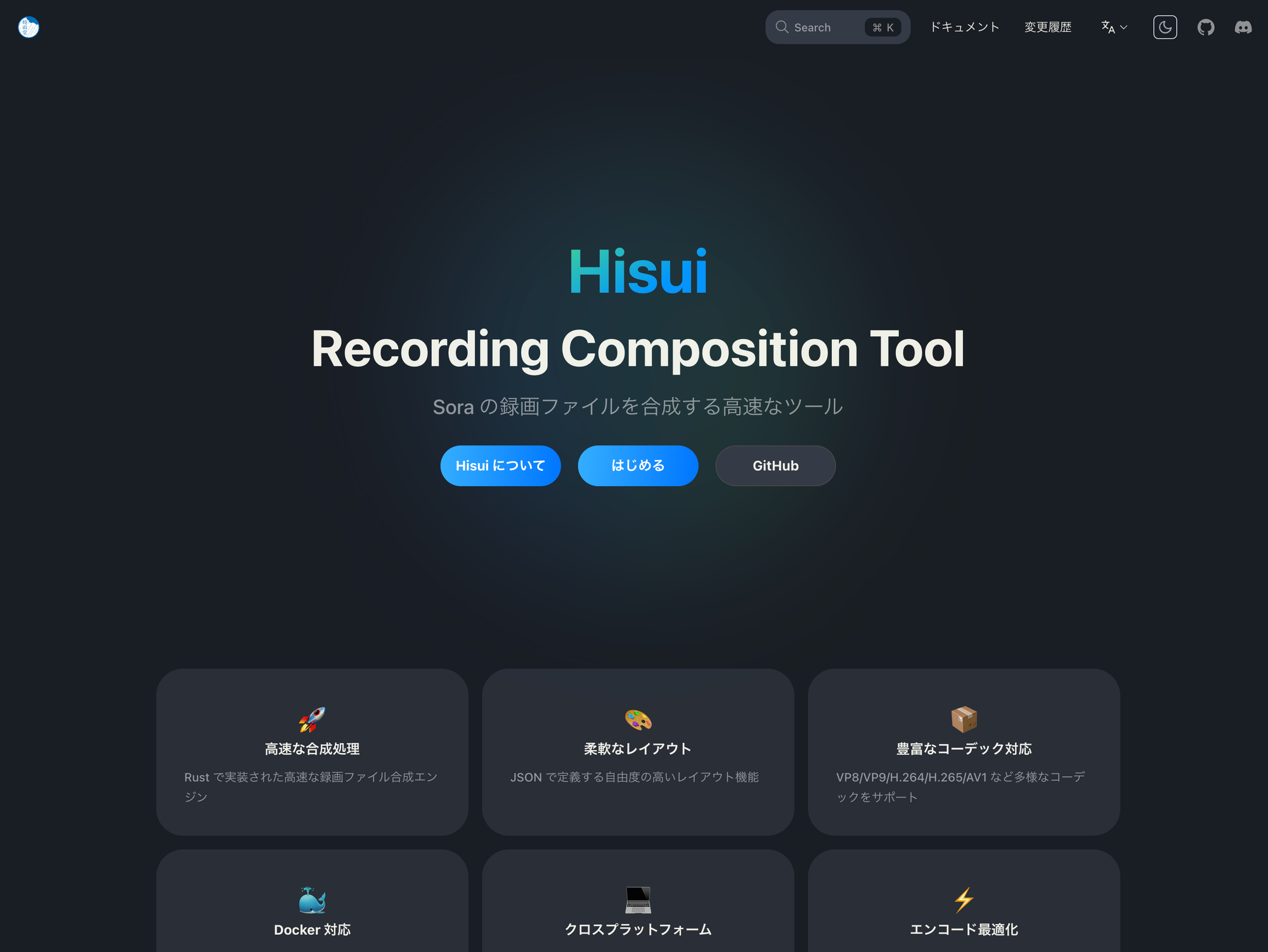
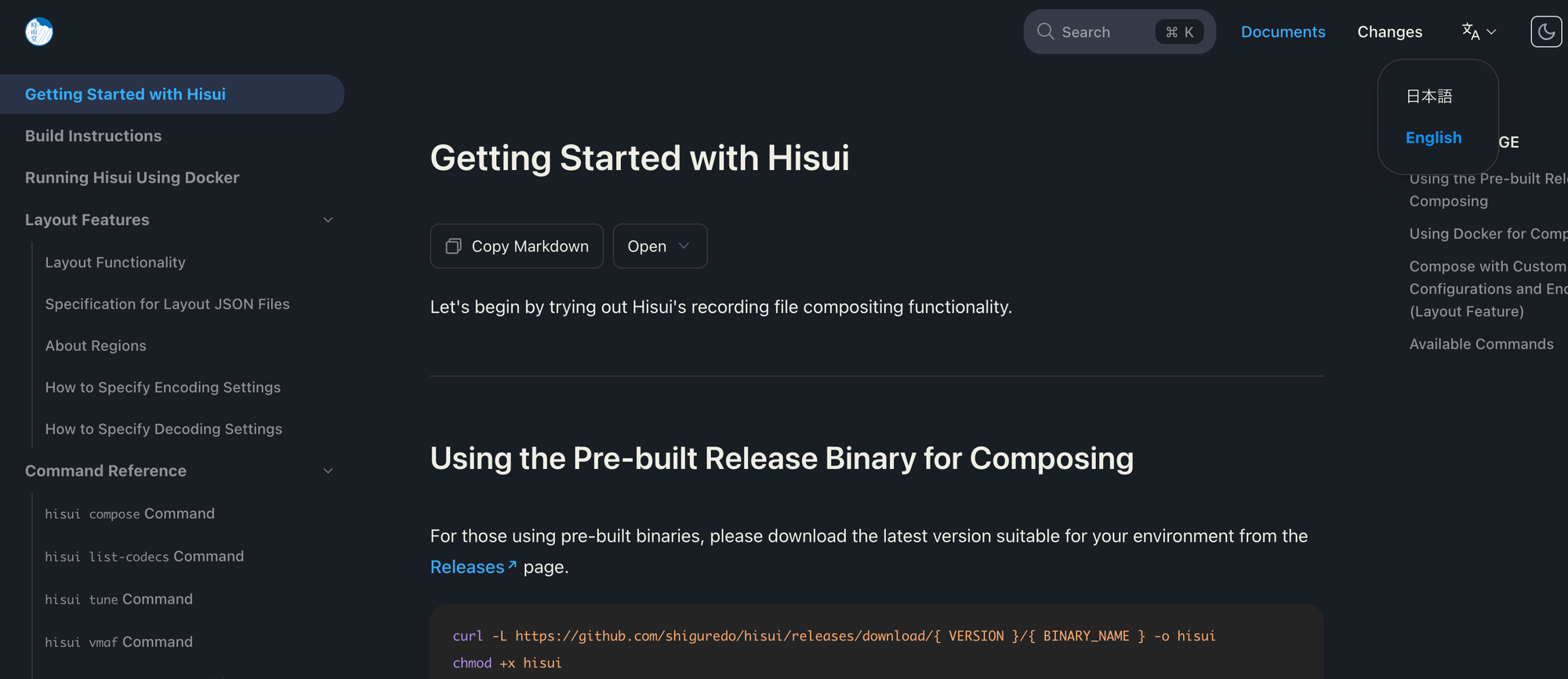
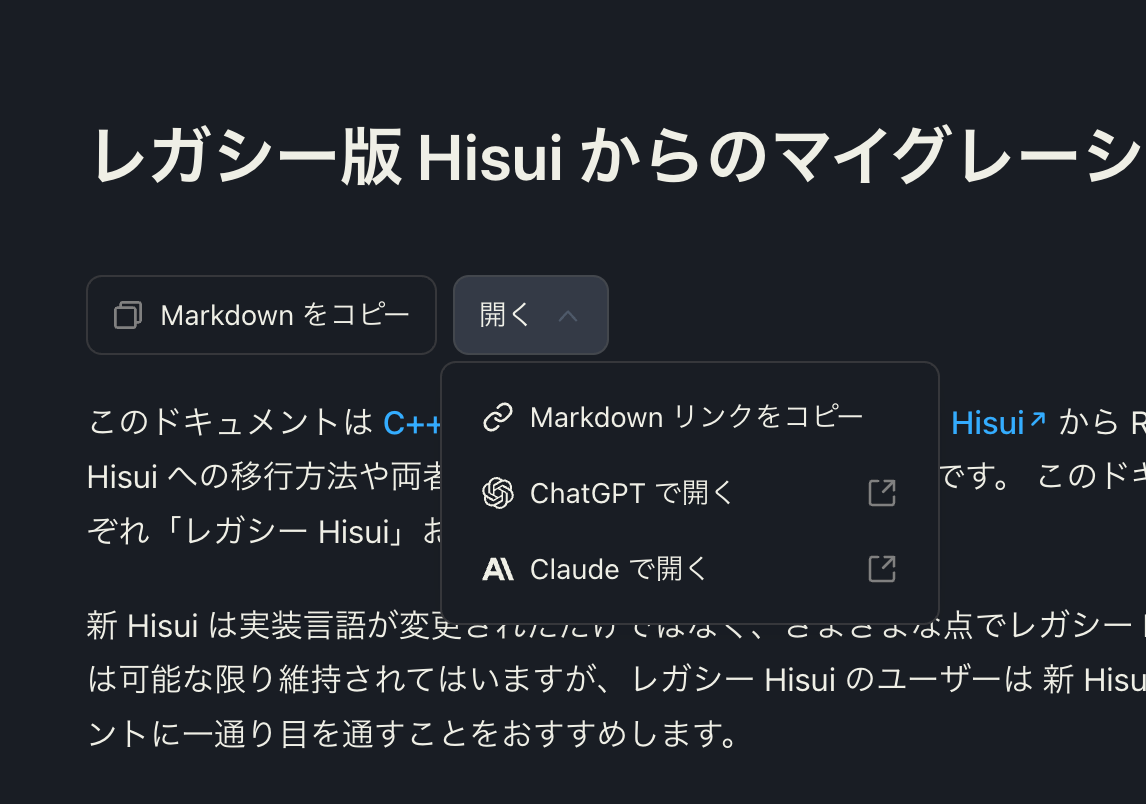
Rspress で作ったお試しページ
色々試してみて、ある程度できるようになりました。ちなみにデザインは一切当ててません。
ということでここからは気になるだろうと勝手に思った点を FAQ 形式で。
rst から md はどうやったの?
Claude Code が全部やってくれた。label からアンカー id も綺麗に変更してくれた。ありがたい限り。
Rspress 使ってる人いなくない?
日本語情報はほぼない。ただ今は LLM に Rspress のソースコードを解析させれば特に困ることはない。あと Issue や PR が放置されていない。
ビルド早い?
早い、すごい。意味がわからない。
MDX どう?
React で拡張し放題なのはいい。結局「ここにこれを作りたい」をやろうと思ったらカスタマイズ一択なので、それが MDX で頑張るしかないと割り切れる。
日本語全文検索どうするの?
最初は今使ってる Meilisearch を移植しようと思っていたが、諦めた。なので DuckDB-Wasm (DuckDB fts) と Lindera-Wasm によるオフライン日本語全文検索 plugin を作り込む予定。
R2 から duckdb ファイルをダウンロードして OPFS に展開して保存するかたち。新しい duckdb ファイルがあれば最新版をダウンロードする仕組み。つまりサーバーレス日本語全文検索を実現することにした。
duckdb ファイルは GitHub Actions で Python で Chunking して lindera-python で分かち書きしてインデックスはって R2 にアップロードする仕組みを作る。
雑感
Rspress は触ってまだ数日だが、よくできているなという感想。ただ結局日本語全文検索がめんどくさい。DuckDB-Wasm でうまくいくといいのだが。