オフライン日本語全文検索 Mikan
自社ドキュメントを reStructuredText(rst) から Markdown (md) へ切り替えて、ドキュメントツールも Sphinx から Rspress へと切り替えているが、ここで一番課題になるのは日本語全文検索である。
今までは Meilisearch を自前でサーバーを立てて、そこで Meilisearch が提供している docs-scraper というスクレイピングツールを公開済みのドキュメントに対して利用し、docs-searchbar.js を Sphinx 独自テーマに組み込むという実現していた。
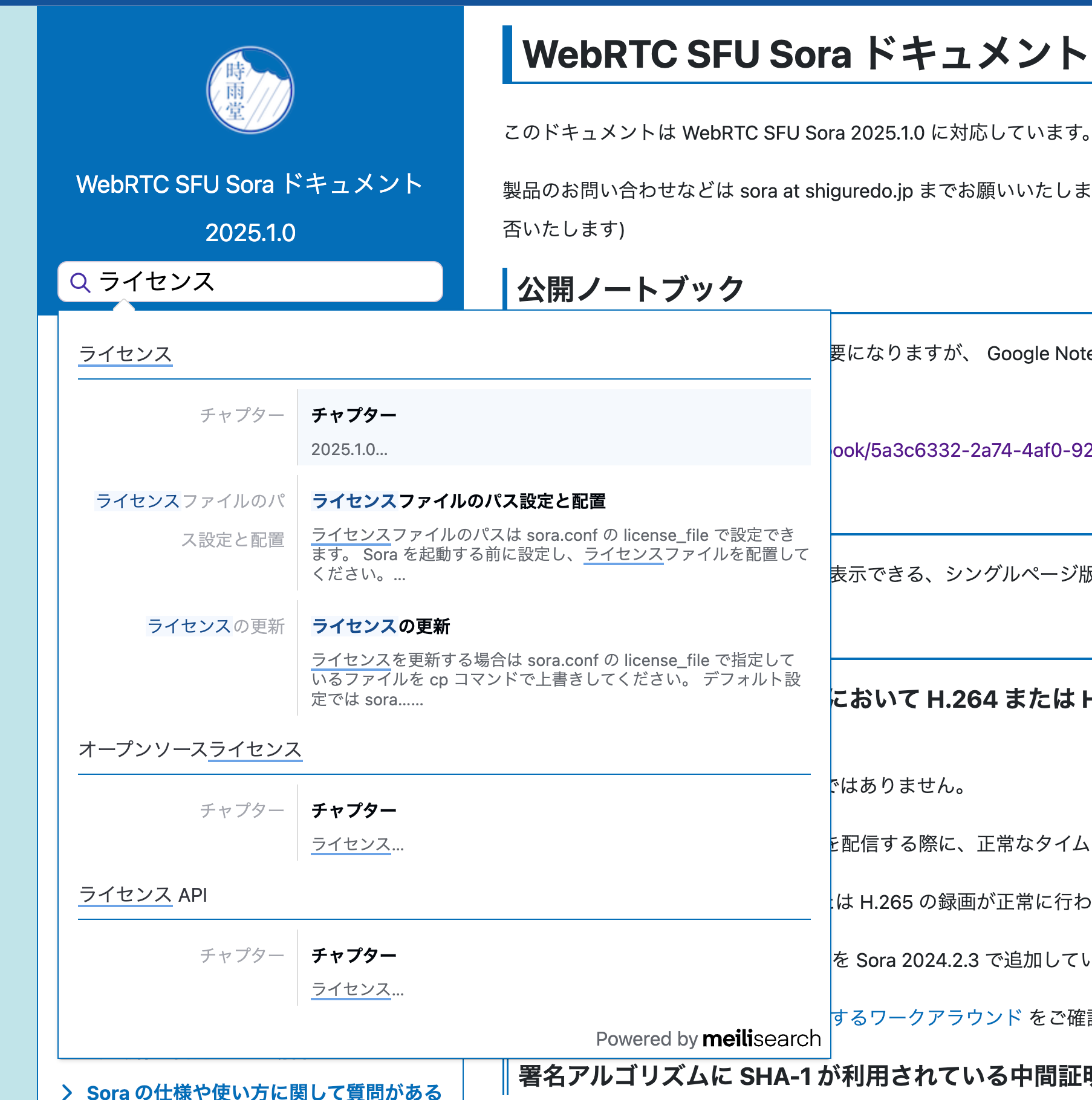
ただ、これがまた Sphinx 拡張のメンテナンスはほぼ不要だが、少しいじろうとすると独自なのでツライ。そして何より Meilisearch の運用がツライ。Meilisearch はかなり高頻度でアップデートするし、docs-scraper と docs-searchbar.js はクラウドサービスでのみ提供で、OSS のメンテナンス終了のお知らせになってしまった。
ということで、今回は運用コストを下げつつ、自分たちでコントロールできるオフライン日本語全文検索を採用する事にした。
まず Rspress に組み込む前に、どこまで作れるかを試しに作ってみることにした。
オフライン日本語全文検索 Mikan
とりあえず名前を社員に考えて貰った、名前大事。時雨堂の製品は全て「色」の名前にしている。今回は蜜柑色。
オフラインつまりブラウザで通信せずに利用できるようにすること。検索用のデータベースを一度ダウンロードしたらもう通信を発生させない。そのためには OPFS や DuckDB-Wasm や Lindera-Wasm を利用する。
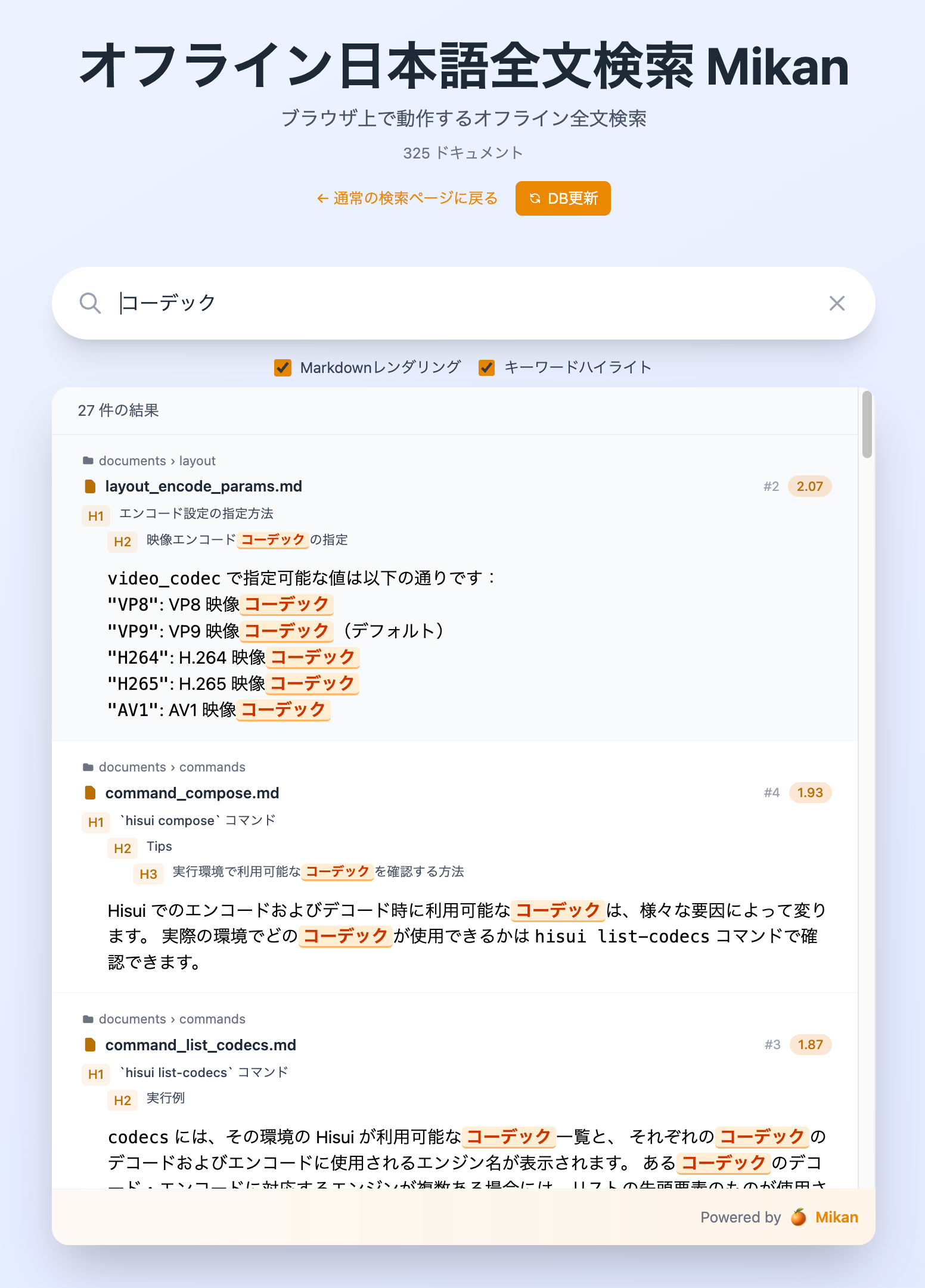
自社製品の Markdown で書かれたドキュメントを Python を利用してうまいこと DuckDB へ保存してそれを Cloudflare R2 へ保存。ブラウザは R2 から DuckDB ファイルをダウンロードしてきて OPFS へ保存。
OPFS 保存した DuckDB ファイルを DuckDB-Wasm へ展開するという仕組み。検索時には Lindera-Wasm で分かち書きした検索条件を DuckDB-Wasm 上で DuckDB FTS (Full Text Search) を利用して検索する仕組み。
サクサク
まず検索自体はできるようになった。次は「検索結果からオリジナルのドキュメントに飛ばす」という作業が必要になる。
これにはアンカー ID が必要になるが、Markdown はアンカー ID をうまいこと作ってくれない。ただ Rspress ではアンカー ID を ## スパム {#spam} みたいに指定できるのだが、これをどううまく使うかはまだたどり着けてないので今後の課題。
データベースの作成
ドキュメントは更新されるため、そのたびにデータベースを再生成して再インデックスを行う必要がある。これを自動化する仕組みを考える必要がある。
今のところは GitHub Actions を作って、ドキュメントが更新されるたびに DuckDB ファイルを更新して R2 に上げるという仕組みを用意する予定。
利用者は最新のドキュメントと一致している DuckDB ファイルを自動でダウンロードする想定。
今後
まずは Rspress に組み込むまでコツコツ作り込んでいく。課題は多いがオフラインになることでサーバの運用が不要になる。ただ類義語やタイプミス耐性などをどうするかなどの課題も残る。データチャネル は DataChannel でも検索に引っかかってほしいし、レガシー は レガスー でも引っかかって欲しかったりするわけで。
課題は多いが、まずは動くものを作ってサクッと置き換えてしまいたい
RAG
ちなみに現時点ではキーワード検索のみだが、Python 側ではベクトル検索とリランカーを組み合わせたハイブリット検索まで実装済みなので、オフライン検索はキーワード検索のみ、オンラインの場合はハイブリッド検索みたいな構成を取りたいと考えている。結局サーバー運用しなければならないが。
また検索システムができれば簡易的な RAG も Claude Haiku 4.5 を利用すれば実現できそうと考えている。ベクトル検索で取得した関連情報を Haiku に説明させるなどもできるだろう。
雑記
ついに自作検索システムに手を出してしまった。ほぼ娯楽に近い。運用が楽にはなるが、結局ベクトル検索やリランカー、RAG と広げていく場合はサーバー運用は必要になる。
とはいえ、ドキュメントの検索システムは凄く重要だと考えている。ドキュメントの検索結果がしょぼいと「その製品を使うモチベーション」も凄く下がるからだ。自分も含め、検索に対して期待値凄く高い。
とりあえず年内にはすべてのドキュメントを Rspress と Mikan に置き換える予定。Mikan は Rspress の Plugin として公開したり、Mikan 自体の仕組みも OSS として公開できたりしたら楽しそうではある。とはいえ当面クローズドでいくが。