製品ドキュメントは読むのではなく質問する時代
VS Code の GitHub Copilot が MCP クライアントとして動作する仕組みが追加されたので、Copilot から気軽に自社製品の質問ができたら、快適ではないだろうか?考えた。
そこで、ハルシネーションをできるだけ少なくし、かつ安価で自社製品ドキュメントへの質問ができる仕組みを作ってみることにした。ちなみに LLM 系の知識はほぼ無い。
できあがった Sora Document MCP (Local)
GitHub Copilot + Sora Document MCP デモ
まぁまぁの速度で、質の高い回答を箇条書きで返してくれるようにはなった。
仕組みについて
自社製品のドキュメントは Sphinx というフレームワークをを利用しており、reStucturedText (以降 rst) というマニアックなもので書かれている。この rst を LangChain と Unstructured を利用してうまい事分割し、分割された非構造化されたテキストを OpenAI Embeddings API でベクトル化して、Vector Similarity Search Extension (以降 DuckDB-VSS) に詰め込んだ。
MCP クライアントから送られてきた検索クエリーを OpenAI Embeddings API でベクトル化して、DuckDB-VSS で SQL で検索をかけた結果を JSON 化して MCP クライアント に返している。
つまり DuckDB を利用したシンプルな RAG を MCP 経由で実現しただけということになる。
費用について
Open AI Embeddings API が想像以上に安い。100 万トークンで 0.02 ドル、150 円換算で 3 円。1 回の検索クエリーが 100 トークンだとしても、1 万回検索されて 3 円、これは安い。
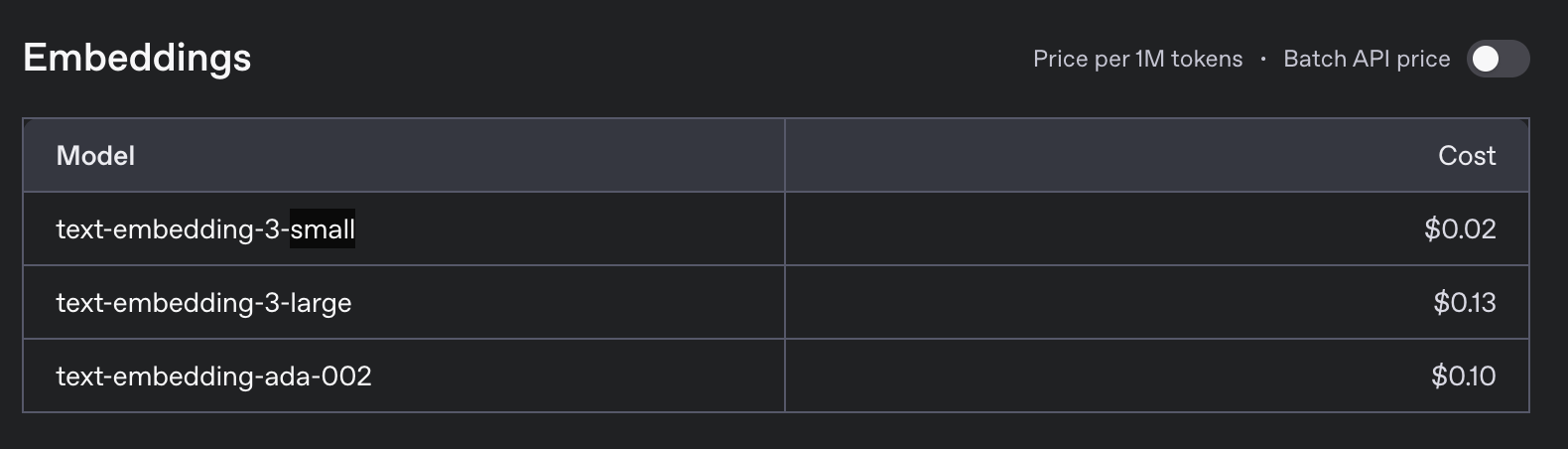
ベクトル化も 1 ドキュメント 3 円で事足りるレベルのドキュメント量しかない。どんなにドキュメントが多くなっても 100 円行く事は無いだろう。
スケールについて
DuckDB-VSS 自体は OSS かつ、組み込み型のデータベースなので既存のバックエンドサーバーから利用するだけで良い。どうせドキュメントなので読み込み専用ということもあり、全てのバックエンドサーバーに対して同じファイルを置けば良いだけ。
例えば GitHub Actions を利用して定期的に rst をベクトル化して DuckDB データベースファイルを生成し、S3 などに置いておき、それをバックエンドサーバーがダウンロードする仕組みを作れば、何も考えずに最新版のドキュメントを提供できる。
さらに言うなら、ドキュメントをベクトル化した DuckDB データベースファイルを誰でもダウンロードできるようにしても特に困ることはない。むしろ利用社側で実行してくれれば負荷をオフロードできる。クエリーをベクトル化する OpenAI Embeddings API 部分はさすがに自費になるが。
ちなみに、自社ではバックエンドは Go で書いてるが、使い方も Go から DuckDB を呼び出すだけ。それも読み込み専用なので並列アクセスもできるので、ここでも特に困ることはない。
結局、沢山アクセス来てもボトルネックになるのは OpenAI API だけ。ここはお金で殴るところであって、技術で頑張るところではないと判断した。
まとめ
これ系の仕組みは顧客に提供するにあたり、ハルシネーションが気になっていたのだが、実際実現してみると、想像以上に間違いがなかった。社員たちで集まって色々 VS Code 経由で質問してみたりしたが、ほぼほぼ間違いの無い回答を返してきたので、これはいけると判断した。
仕組み的にもそんなに難しい事をやっていないため、知識が無い自分でも実現ができたのも良かった。今後は顧客が気軽に利用できる仕組みを提供していきたい。
サンプルコード生成やコード提案
SDK や自社製品と連携するアプリを作るためのサンプルコード生成やコード提案をする仕組みってのを実現したいが、RAG の延長でいけるのかどうかも全くわかっていないので色々試していきたい。